// writeup
Practical Binary Analysis, Ch. 1: Anatomy of a Binary
Notes on Chapter 1 of Practical Binary Analysis by Dennis Andriesse, plus my solutions to the exercises.
# ── preprocessing ────────────────────────────────────────────────
gcc -E -P <file> # -E stop after cpp
# -P omit line markers (# directives)
# ── compilation ──────────────────────────────────────────────────
gcc -S -masm=intel <file> # -S emit .s, stop before assembly
# -masm=intel Intel syntax (≠ AT&T default)
# ── assembly ─────────────────────────────────────────────────────
gcc -c <file> # compile + assemble → relocatable .o, no link
# ── full pipeline ────────────────────────────────────────────────
gcc <file> -o binary # dynamically linked executable (default)
gcc <file> -o binary -static # statically linked, all deps embeddedfile <file> # ELF type + arch: relocatable / executable / shared object
readelf --syms <file> # symbol table (long form of -s)
readelf -r <file> # relocation entries: what the linker must patch and how
objdump -M intel -d <file> # disassemble (Intel syntax)
objdump -sj .rodata <file> # hex+ascii dump of .rodata section
strip --strip-all <file> # remove .symtab/.strtab (runtime keeps .dynsym)Pipeline overview
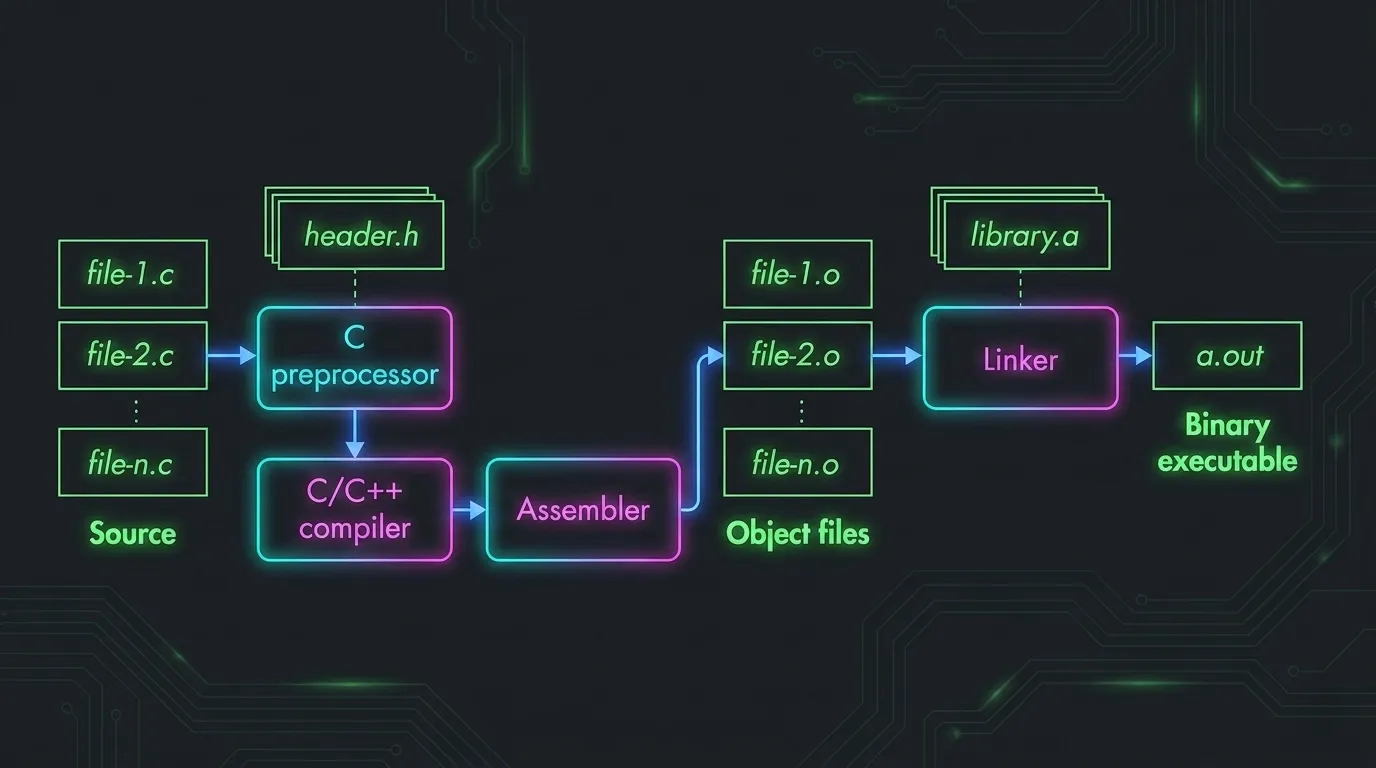
Preprocessing
cpp expands #include, #define, and conditionals into a single translation unit of pure C, with no directives left in the output. Token pasting (##), stringification (#), and predefined macros (__FILE__, __LINE__, __COUNTER__) are resolved here, before any type-checking or code generation occurs.
Compilation
GCC lowers the translation unit through its internal IR (GIMPLE → RTL) to architecture-specific assembly. The optimization level is the critical variable for reverse engineering: -O0 emits a nearly 1:1 mapping to the C source: every variable on the stack, every expression a separate instruction. From -O2 up, the compiler inlines aggressively, eliminates dead branches, unrolls loops, and can merge or reorder functions entirely, breaking the structural correspondence you’d expect. Symbolic labels are still present in the .s output regardless of level.
Assembly
as translates mnemonics to opcodes and produces a relocatable ELF object (.o). External references have no resolved address yet; they are recorded as relocation entries in .rela.text (RELA on x86-64: offset + type + symbol + addend), pointing the linker at every site that needs patching. file reports the output as ELF 64-bit LSB relocatable; a shared library built with -fPIC -shared comes out as shared object, position-independent with no fixed load address.
Key sections in a .o:
.text: executable code.data: initialized globals; present in file, mapped RW.bss: zero-initialized globals; no file space, kernel zero-fills on load.rodata: string literals and const arrays; mapped RO, inspect withobjdump -sj .rodata.symtab/.strtab: full symbol table; stripped in release builds.dynsym: export/import table for the dynamic linker; survivesstrip --strip-all
Linking
ld (invoked by gcc) consumes all .o files and library inputs, resolves every relocation entry, assigns final virtual addresses, and emits the executable ELF.
Static (-static) merges all .text / .data / … sections from .o files and .a archives, resolving all relocations to absolute addresses. It is fully self-contained, with no PT_INTERP, no PLT indirection, and direct calls. The binary is larger (it carries full libc), but there are no runtime dependency surprises; preferred for forensics and sandboxed environments.
Dynamic (default) leaves external symbols as UNDEF in .dynsym. A PT_INTERP segment names the runtime linker (/lib64/ld-linux-x86-64.so.2), which maps the needed .sos and resolves symbols at load time, or lazily on first call via PLT/GOT: each external call goes through a PLT stub that on first invocation falls through to the resolver, patches the GOT entry with the real address; subsequent calls jump through the GOT directly.
LTO (-flto) defers optimization to link time. GCC stores GIMPLE IR in object files instead of machine code; ld then runs a second optimization pass across all translation units simultaneously, enabling cross-TU inlining and dead function elimination. From a RE perspective, LTO-built binaries have no function-level correspondence to source files, and aggressively inlined code makes CFG reconstruction significantly harder.
ldd ./binary # runtime shared lib dependencies
readelf -d ./binary | grep NEEDED # required .so from ELF dynamic section
readelf -W --syms ./binary | grep UNDEF # symbols resolved at runtime by ld.so
objdump -M intel -d ./binary # disassemble: external calls appear as plt@FUNC
strip --strip-all ./binary # remove .symtab/.strtab (keeps .dynsym)After strip --strip-all, function names and local symbols are gone; only the exports and imports the dynamic linker depends on remain. CFG recovery falls back to heuristics: function prologue patterns, cross-reference analysis, and section boundary detection.
Debug info
ELF + DWARF. Debug info is embedded directly as dedicated sections (.debug_info, .debug_line, .debug_abbrev, …). strip --strip-debug removes these without touching the symbol table; strip --strip-all removes both. Shipped ELF binaries are typically fully stripped.
PE + PDB. Windows uses a separate PDB (Program Database) file linked to the binary via a GUID in IMAGE_DEBUG_DIRECTORY. The binary carries almost no debug info itself, and the PDB is rarely shipped, making it absent for most RE work unless indexed by a symbol server (symsrv).
ELF loading
Linking produces a file on disk. Loading turns it into a live process, a choreography across three actors: the kernel (parses ELF, creates the initial address space), the dynamic linker (ld.so, at /lib64/ld-linux-x86-64.so.2, a position-independent shared library that bootstraps the runtime before any user code runs), and libc, the standard C library (libc.so.6) providing malloc, printf, exit, and the startup/shutdown scaffolding every C program depends on.
fork + execve. The shell calls fork() to clone itself, then execve(path, argv, envp) in the child. The kernel’s do_execve handler tears down the existing address space and begins constructing a new one from the binary on disk.
Kernel reads ELF header. The 64-byte ELF header supplies everything needed: magic bytes (\x7fELF), e_type (ET_EXEC for a fixed-address executable, ET_DYN for a PIE), e_machine (EM_X86_64), and e_phoff, the file offset to the program header table listing all PT_* entries.
Kernel maps PT_LOAD segments. For each PT_LOAD entry the kernel issues an mmap(): the file range is mapped at the specified virtual address with permissions matching the segment flags (R-X for code, RW- for data). It is demand-paged, so there is no physical I/O until the first access triggers a page fault.
Kernel maps ld.so from PT_INTERP. If a PT_INTERP segment is present (every dynamically linked binary has one), the kernel reads the interpreter path it contains (/lib64/ld-linux-x86-64.so.2), opens that file, and maps its own PT_LOAD segments at a fresh ASLR base address. ld.so is itself a PIE, so it runs fully position-independent and must self-relocate before it can call any of its own functions.
Kernel prepares the initial stack. Before handing over control, the kernel writes the initial stack frame: argc, argv[] and envp[] pointer arrays (each null-terminated), then the auxiliary vector, a sequence of AT_* key-value pairs that pass kernel-internal state to userspace without a syscall:
AT_PHDR/AT_PHNUM: address and count of the main executable’s program headers; letsld.solocatePT_DYNAMICAT_ENTRY: the main executable’s entry point (_start); whereld.sowill jump at the very endAT_BASE:ld.so’s own load base; needed for its self-relocation passAT_RANDOM: 16 kernel-generated random bytes; seeds the stack canary and glibc’s ASLR offsets
LD_SHOW_AUXV=1 ./a.out 2>/dev/null | grep -E "AT_PHDR|AT_PHNUM|AT_ENTRY|AT_BASE|AT_RANDOM|AT_PAGESZ|AT_INTERP"
AT_PAGESZ: 4096 # memory page size (arch constant, no syscall needed)
AT_PHDR: 0x555555554040 # main executable program header table
AT_PHNUM: 13 # number of PT_* entries in that table
AT_BASE: 0x7ffff7fc5000 # ld.so load base (ASLR randomised each exec)
AT_ENTRY: 0x555555555050 # _start, ld.so jumps here after relocation
AT_RANDOM: 0x7fffffffde39 # 16 random bytes (stack canary seed)Dynamic linker maps shared libraries. ld.so reads the main executable’s PT_DYNAMIC segment and walks its DT_NEEDED entries, each of which names a required shared object (libc.so.6, libm.so.6, …). It resolves paths through DT_RUNPATH, LD_LIBRARY_PATH, and /etc/ld.so.cache, then maps each library’s PT_LOAD segments at ASLR-randomised addresses. The process is recursive: each newly loaded library may declare its own DT_NEEDED entries.
Dynamic linker applies relocations. With all libraries resident, ld.so processes the relocation tables (.rela.dyn / .rela.plt): for each entry, the target symbol is resolved across all loaded objects’ .dynsym tables and the result is written into the target slot, whether a GOT entry or an absolute pointer in .data. After this pass, all eagerly-bound symbols are fully resolved; PLT entries are primed for lazy resolution on first call.
Constructors, .init_array. ld.so calls functions listed in .init_array in dependency order: library constructors first (TLS setup, libc internal init), then the executable’s own. C functions annotated __attribute__((constructor)) land here, and they run before main with no explicit call in the source.
Dynamic linker jumps to _start. ld.so reads AT_ENTRY from the auxiliary vector and transfers control to the main executable’s entry point. This is _start, injected by the GCC linker script from crt1.o, and it never appears in the C source.
_start → __libc_start_main. _start zeroes rbp (marking the outermost stack frame for unwinders), extracts argc, argv, and envp from the initial stack layout, and calls __libc_start_main(main, argc, argv, …). libc is already fully mapped and relocated, so the call goes through the GOT like any other external symbol.
libc calls main. __libc_start_main installs atexit handlers, runs any remaining init callbacks, then calls main(argc, argv, envp). On return, exit() flushes stdio buffers, fires atexit callbacks, and issues the exit_group(status) syscall, terminating every thread in the process.
Exercises
1. Locating functions
Write a C program that contains several functions and compile it into an assembly file, an object file, and an executable binary, respectively. Try to locate the functions you wrote in the assembly file and in the disassembled object file and executable. Can you see the correspondence between the C code and the assembly code? Finally, strip the executable and try to identify the functions again.
#include <stdlib.h>
#include <stdio.h>
float multiply(float a, float b) { return a *= b; }
float divide(float a, float b) { return a /= b; }
void show(char* str) { printf("%s\n", str); }
int main(int argc, char* argv[]) {
printf("%s\n", "hello!");
show("World");
float c = multiply(divide(4.0, 2.0), 5.0);
printf("%f\n", c);
return 0;
}gcc -S -masm=intel locatingfunctions.c # → .s labels are plain text in the source
gcc -c locatingfunctions.c # → .o external calls show as 0x0 + reloc entry
gcc locatingfunctions.c -o a.out # → executable, symbols intact
strip --strip-all a.out -o a2.out # → stripped copyIn the .s file, function names appear as plain assembly labels (multiply:, divide:, …); they are source text. In the .o, they are symbol table entries; calls to external functions show address 0x0 with a relocation entry pointing the linker at the call site. In the linked binary, all relocations are resolved to final virtual addresses.
With symbols (a.out):
0000000000001149 <multiply>:
1149: 55 push rbp
114a: 48 89 e5 mov rbp,rsp
114d: f3 0f 11 45 fc movss DWORD PTR [rbp-0x4],xmm0 ; spill a (-O0)
1152: f3 0f 11 4d f8 movss DWORD PTR [rbp-0x8],xmm1 ; spill b
1157: f3 0f 10 45 fc movss xmm0,DWORD PTR [rbp-0x4] ; reload a
115c: f3 0f 59 45 f8 mulss xmm0,DWORD PTR [rbp-0x8] ; xmm0 = a * b
1161: f3 0f 11 45 fc movss DWORD PTR [rbp-0x4],xmm0 ; store result
1166: f3 0f 10 45 fc movss xmm0,DWORD PTR [rbp-0x4] ; reload for return
116b: 5d pop rbp
116c: c3 ret
000000000000116d <divide>: ; identical structure, divss instead of mulss
...
1180: f3 0f 5e 45 f8 divss xmm0,DWORD PTR [rbp-0x8]
...
1190: c3 ret
0000000000001191 <show>:
...
11a4: e8 87 fe ff ff call 1030 <puts@plt> ; printf("%s\n") → puts
11ab: c3 ret
00000000000011ac <main>:
...
11c5: e8 66 fe ff ff call 1030 <puts@plt> ; printf("%s\n","hello!") → puts
11d4: e8 b8 ff ff ff call 1191 <show>
11eb: e8 7d ff ff ff call 116d <divide>
1200: e8 44 ff ff ff call 1149 <multiply>
122e: e8 0d fe ff ff call 1040 <printf@plt> ; %f needs real printf; multiply / divide: standalone stubs, 2 instructions, no frame, no spills
0000000000001190 <multiply>:
1190: f3 0f 59 c1 mulss xmm0,xmm1
1194: c3 ret
00000000000011a0 <divide>:
11a0: f3 0f 5e c1 divss xmm0,xmm1
11a4: c3 ret
; show: tail call, the function body IS the jump to puts
00000000000011b0 <show>:
11b0: e9 7b fe ff ff jmp 1030 <puts@plt>
; main: multiply / divide / show all inlined, arithmetic constant-folded to a single value
0000000000001050 <main>:
1050: sub rsp,0x8
1054: lea rdi,[rip+0xfa9] ; "hello!"
105b: call 1030 <puts@plt> ; printf("hello!\n") → puts
1060: lea rdi,[rip+0xfa4] ; "World"
1067: call 1030 <puts@plt> ; show("World") inlined → direct puts
106c: movsd xmm0,QWORD PTR [rip+0xfa4] ; multiply(divide(4.0,2.0),5.0) = 10.0 precomputed
1074: mov eax,0x1 ; 1 xmm arg for printf varargs
1079: lea rdi,[rip+0xf91] ; "%f\n"
1080: call 1040 <printf@plt>
1085: xor eax,eax ; return 0
1087: add rsp,0x8
108b: ret0000000000001030 <puts@plt>:
1030: ff 25 ca 2f 00 00 jmp QWORD PTR [rip+0x2fca] ; jump through GOT slot
1036: 68 00 00 00 00 push 0x0 ; reloc index for resolver
103b: e9 e0 ff ff ff jmp 1020 <puts@plt-0x10> ; → ld.so resolver
; First call: GOT slot → resolver → patches GOT with real puts address
; All subsequent calls: GOT slot → libc puts directly (no resolver overhead)Stripped (a2.out):
After strip --strip-all, the entire .text section becomes one anonymous blob. There are no function labels; only PLT entries (from .dynsym) and ELF section names survive. Calls that previously referenced named symbols now reference offsets relative to the nearest surviving symbol:
; ── non-stripped ────────────────────────────────────
0000000000001149 <multiply>: ; function label present
11d4: e8 b8 ff ff ff call 1191 <show>
11eb: e8 7d ff ff ff call 116d <divide>
1200: e8 44 ff ff ff call 1149 <multiply>
; ── stripped ─────────────────────────────────────────
0000000000001050 <.text>: ; entire section = one blob, no function labels
11d4: e8 b8 ff ff ff call 1191 <printf@plt+0x151> ; was: <show>
11eb: e8 7d ff ff ff call 116d <printf@plt+0x12d> ; was: <divide>
1200: e8 44 ff ff ff call 1149 <printf@plt+0x109> ; was: <multiply>
; opcodes are byte-for-byte identical, only the annotations differ2. Sections
As you’ve seen, ELF binaries (and other types of binaries) are divided into sections. Some sections contain code, and others contain data. Why do you think the distinction between code and data sections exists? How do you think the loading process differs for code and data sections? Is it necessary to copy all sections into memory when a binary is loaded for execution?
Why the distinction exists:
The core reason is memory protection. The CPU’s MMU enforces per-page permission bits set by the OS: code pages are mapped R-X (read + execute, not writable), data pages RW- (read + write, not executable). Separating them into distinct sections lets the linker group them into ELF segments with matching permissions, which the loader then passes to mmap().
How loading differs (code vs data):
The kernel ELF loader (load_elf_binary) and ld.so work with segments (program header entries), not sections. Each PT_LOAD segment groups sections of the same permission class and is mapped with a single mmap() call:
Type Offset VirtAddr FileSiz MemSiz Flg
LOAD 0x001000 0x0000000000001000 0x000249 0x000249 R E # code: r-x
LOAD 0x002db0 0x0000000000003db0 0x000270 0x000278 RW # data: rw-
# ^FileSiz ^MemSiz
# ^^^^^ .bss adds to MemSiz but not FileSizIs it necessary to load all sections?
No, and the sections/segments split is precisely what makes this possible. Sections are the linker/debugger view of the file. Segments are the runtime view. Only sections that fall inside a PT_LOAD segment are ever mapped; everything else exists only on disk:
Section to Segment mapping:
Segment Sections
...
03 .init .plt .text .fini # r-x → loaded
04 .rodata .eh_frame_hdr .eh_frame # r → loaded
05 .data .bss .got .dynamic .init_array .fini_array # rw- → loaded
...
# NOT listed in any segment → never mapped:
# .symtab .strtab (stripped anyway in release)
# .debug_info .debug_line .debug_abbrev .debug_str (DWARF)cat /proc/$(pidof binary)/maps
# 555555555000-555555556000 r-xp ... a.out ← .text mapped r-x
# 555555557000-555555558000 r--p ... a.out ← .rodata mapped r
# 555555558000-555555559000 rw-p ... a.out ← .data/.bss mapped rw
# 7ffff7d00000-7ffff7f28000 r-xp ... libc.so ← shared code pages (same physical frames across all processes)